[ICT] Apache Spark 3.3.1 / Scala 環境を5分でデプロイする
ほぼ備忘録です。
秒速を目指しましたが実際は 5分38秒 でした。ソースからビルドしません。
Apache Spark 3.3.1 について → Spark 3.3.1 released | Apache Spark
環境を作るのに時間をかけたくない方へ参考になれば。
Apache Spark とは
Apache Spark は、大規模なデータ処理のための統合分析エンジンです。 Java、Scala、Python、R の高レベルAPIを提供します。 一般的な実行グラフをサポートする最適化されたエンジン。 また、SQL と構造化データ処理のための Spark SQL、Panda のワークロードのための Spark 上の Panda API、機械学習のための MLlib、グラフ処理のための GraphX、増分計算とストリーム処理のための構造化ストリーミングなど、高レベルのツールの豊富なセットもサポートしています。
(引用元/英文:https://spark.apache.org/docs/latest/index.html )
補足:Spark は 分散コレクション RDD / Resilient Distributed Dataset
構築環境
- Windows 11 Home (64ビット), RAM 32GB (おそらく 8GB でも動作します)
- Docker Desktop for Windows
- それなりに高速で安定しているインターネット回線
- https://hub.docker.com/r/apache/spark から概要を読んでおく
その他:ウィルス駆除ソフトがバックグラウンドで起動していても構いません
構築手順
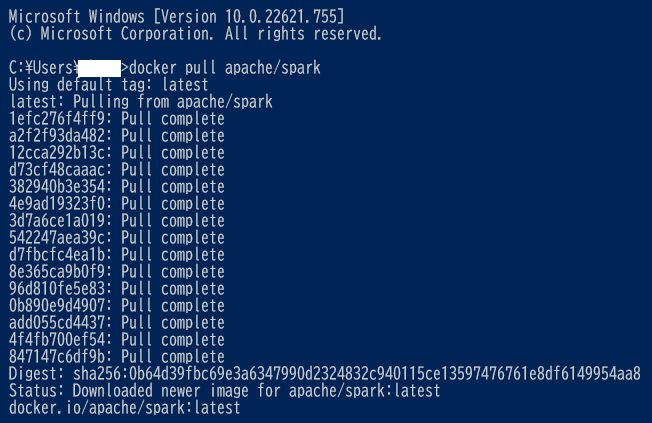
- docker pull apache/spark 投入
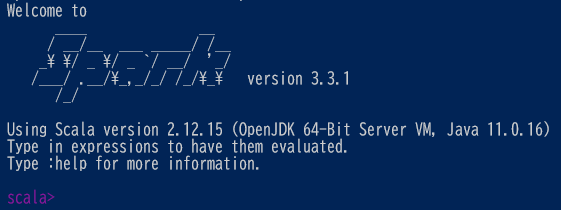
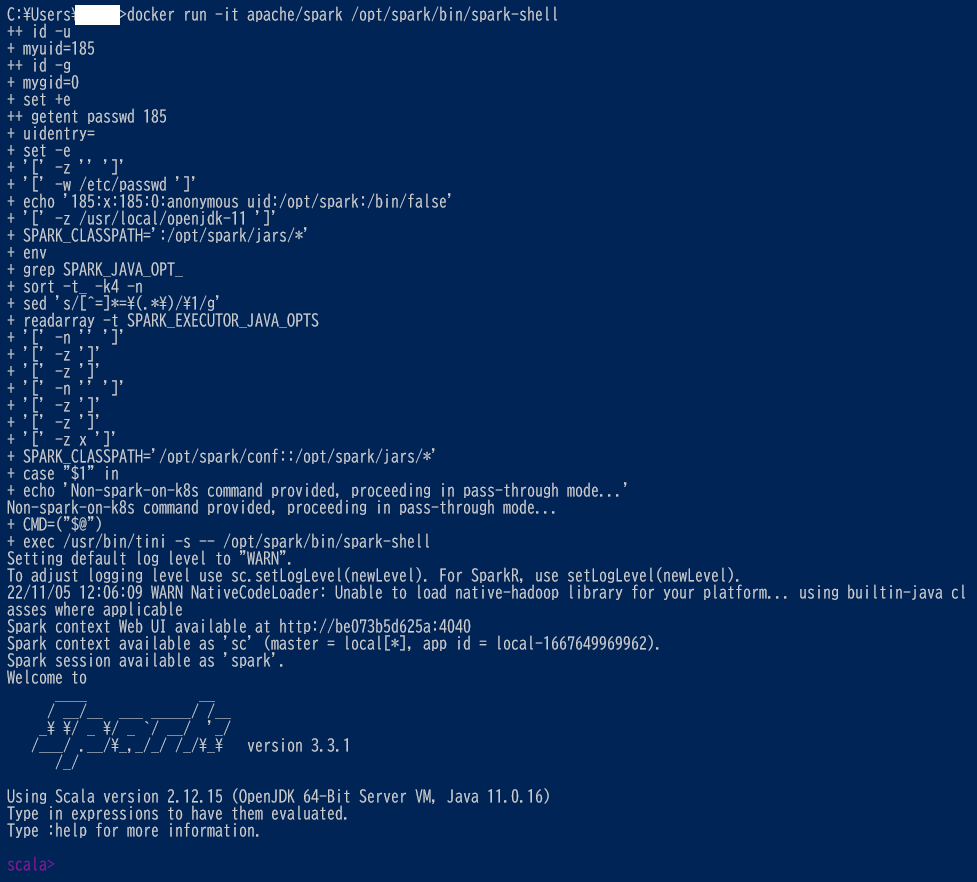
2. 対話型の Scala シェル起動 (scala プロンプトが表示されるまで 5分38秒 でした)
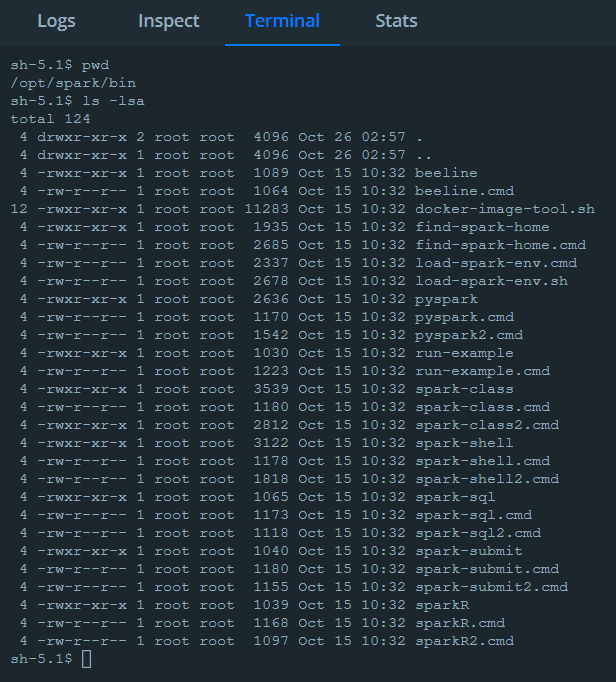
Spark 環境
PATH
/usr/local/openjdk-11/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
JAVA_HOME
/usr/local/openjdk-11
LANG
C.UTF-8
JAVA_VERSION
11.0.16
SPARK_HOME
/opt/spark
補足:Docker Terminal 起動時
/opt/spark/work-dir
コマンド確認
次のコマンド投入すると 1,000,000,000 が返すことを確認。
spark.range(1000 * 1000 * 1000).count()

Docker Terminal でサンプル実行(円周率計算)
sh-5.1$ /opt/spark/bin/run-example SparkPi 10
1回目 Pi is roughly 3.13987113987114
2回目 Pi is roughly 3.142231142231142
3回目 Pi is roughly 3.141271141271141
4回目 Pi is roughly 3.142939142939143
5回目 Pi is roughly 3.140755140755141
演算結果はあまり良くないですねw
他に試せそうなもの
Scala example
github にあります。
<Basic>
https://github.com/apache/spark/tree/master/examples/src/main/scala/org/apache/spark/examples
ここでは割愛します。
以上、ご覧いただきありがとうございました。
![[資格取得] IBM Cloud for Professional Architect v6 (合格体験談)](https://www.fxfrog.com/wp-content/themes/newscrunch/assets/images/no-preview.jpg)





