[ML Study Jams Vol.4] Baseline: Data, ML, AI / 強化学習 Reinforcement Learning: Qwik Start 受講メモ

GSP691 Baseline: Data, ML, AI の 1コマ「Reinforcement Learning: Qwik Start」
https://google.qwiklabs.com/focuses/10285
概要 (Google 翻訳から転記)
機械学習研究の他の多くの領域と同様に、 強化学習(RL)は、画期的な速度で進化しています。他の研究分野で行ったように、研究者たちはディープラーニングを活用して最先端の結果を達成しています。
特に、強化学習はゲームプレイで以前のMLテクニックを大幅に上回り、Atariで人間レベル、さらには世界最高のパフォーマンスを達成し、人間のGoチャンピオンを破り、Starcraft IIなどのより難しいゲームで有望な結果を示しています。
このラボでは、OpenAI Gymが提供するサンプルからモデル化された単純なゲームを作成して、強化学習の基本を学びます 。
(qwiklabs から引用)
ハンズオンの内容メモ
■目的:
- 強化学習の基本的な概念を理解する。
- AI Platform Tensorflow 2.1 Notebookを作成します。
- Githubにあるトレーニングデータアナリストのリポジトリからサンプルリポジトリのクローンを作成します。
- ノートブックにある手順を読み、理解し、実行します。
Deep Q-network (DQN) の概要紹介が Qwiklabs あるので、味わって読むといいと思います。賢明な方には不要でしょうが【DQN は not ドキュソ】です。
筆者の都合により、ダッシュボードは 日本語で操作します。
■Create an AI Platform Notebook
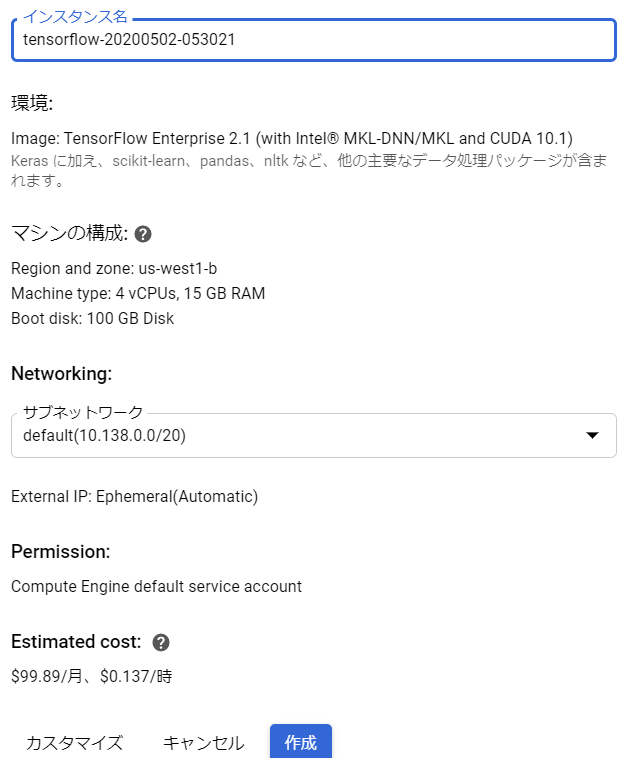
us-west1-b リージョンに 4vCPUs, 15GB RAM / TensorFlow 2.1 without GPU 環境を無償で作ります。Tesla T4 を無償体験してみたいが、我慢。

■JuputerLab Notebook の Terminal 操作でgit clone を実施します。
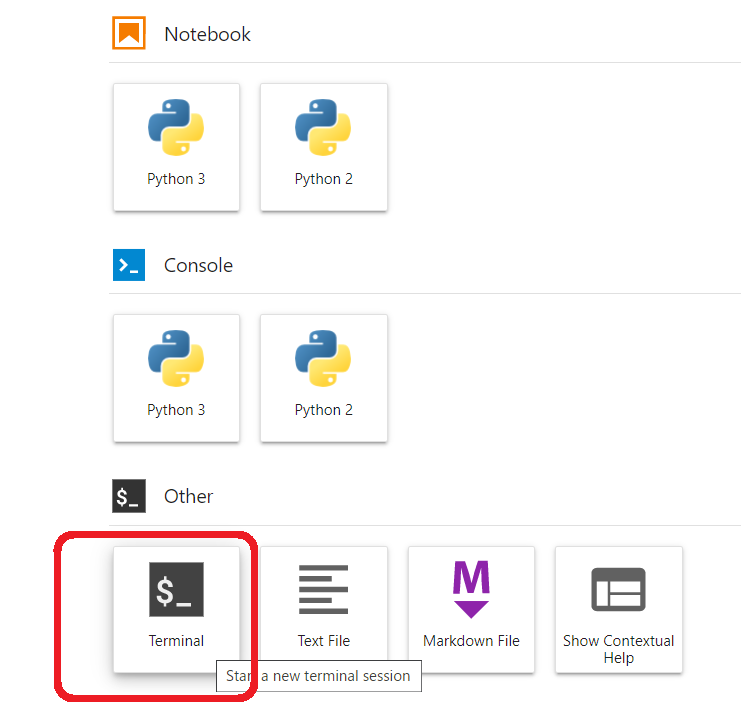
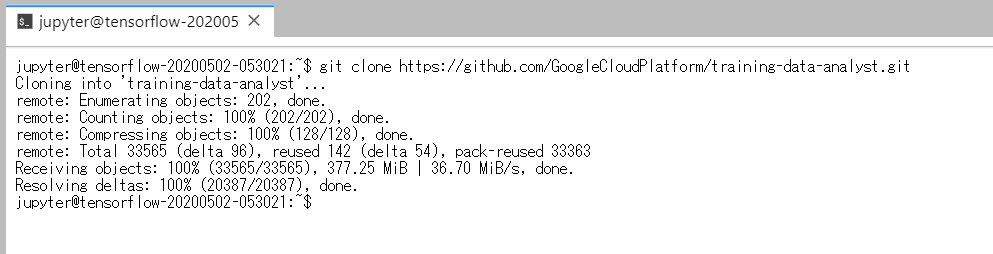
■git clone 実施。
■新しいタブで、training-data-analyst> quests> rl > early_rl > early_rl.ipynb. を開きます。

ラボ終了
blog メモ(スクリーンショット撮影)を作成しなければ、概ね 10分程度で完了すると思います。
Baseline: Data, ML, AI クエスト完了

このクエストは完了。次はどのクエストか、コースへ進もうかな。
ご覧いただき有難うございました。
以上

![[資格取得] IBM Cloud for Professional Architect v6 (合格体験談)](https://www.fxfrog.com/wp-content/themes/newscrunch/assets/images/no-preview.jpg)





