[ML Study Jams Vol.4] Baseline: Data, ML, AI / Dataflow: Qwik Start – テンプレート 受講メモ
GSP192 Baseline: Data, ML, AI の 1コマ「Dataflow: Qwik Start – テンプレート」 注意:45分コマです。
https://google.qwiklabs.com/focuses/1101
概要
このラボでは、Google の Cloud Dataflow テンプレートの 1 つを使用してストリーミング パイプラインを作成する方法を学習します。具体的には、Cloud Pub/Sub to BigQuery テンプレートを使用します。このテンプレートは、Pub/Sub トピックから JSON 形式のメッセージを読み取り、BigQuery テーブルに push します。このテンプレートのドキュメントについては、こちらをご覧ください。
BigQuery でデータセットとテーブルを作成するには、Cloud Shell コマンドラインまたは GCP Console を使用します。いずれかの方法を選択し、ラボの作業を進めてください。両方の方法を試したい場合は、このラボを 2 回行ってください。
(qwiklabs から引用)
ハンズオンの内容
タクシー乗車データ 1,000件を BQ から抽出する。
あれ?と思った箇所①:Storage バケットを作成した後のハンズオン操作
バケットを作成したら、「パイプラインを実行する」セクションまで下にスクロールします。
ほんまに飛ばしていいのか?と思い・・・。Data Flow へ進むと、デフォルトの Data Flow チュートリアルが右ペイン表示するので迷わず「終了」すること。さもなくば、時間が足らなくなります。
あれ?と思った箇所②:DataFlow テンプレートから ジョブを作成
ジョブ名は自由です。↓

先ほど作成したバケットの配下を一時的なロケーションに指定します。↓
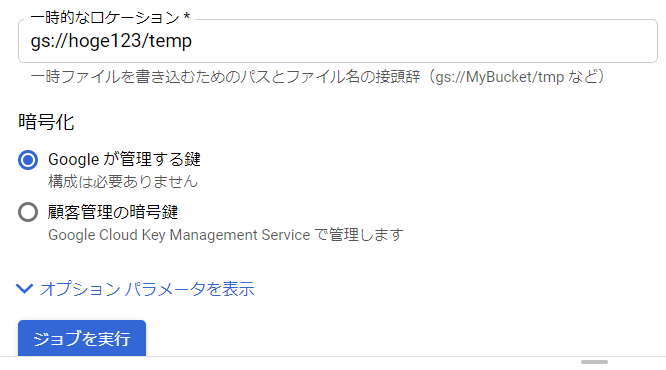
すると、ジョブグラフが表示されて右ペイン[ジョブ情報:実行中] を確認します。↓ なお、確認後は次のパラグラフへ進めます。BQ エディタ操作へ。

あれ?と思った箇所③:クエリエディタでハマる方へ
クエリは、このハンズオン用プロジェクト ID を使うので
例:SELECT * FROM qwiklabs-gcp-03-c7d0f24a6210.taxirides.realtime LIMIT 1000 などを投入してください。
以前、メンターを実施したときに SELECT * FROM `myprojectid.taxirides.realtime` LIMIT 1000 これをそのまま投入して【動作しないよ】と仰られる方がおられましたので。

ラボ終了

このコマ終了に要した時間は 28分ほど。
blog 記事を書きながらなので、まぁまぁサクサク進められたかな。
まだまだコマは続くよ・・・。
ご覧いただき有難うございました。
以上

![[資格取得] IBM Cloud for Professional Architect v6 (合格体験談)](https://www.fxfrog.com/wp-content/themes/newscrunch/assets/images/no-preview.jpg)





